[OS] 프로세스와 스레드
멀티태스킹
CPU가 매우 빠르게 두 프로그램의 코드를 번갈아 수행해 사람이 느낄 때 두 프로그램이 동시에 실행되는 것처럼 느끼는 것.
각 프로그램의 실행 시간을 분할해 마치 동시에 실행되는 것 처럼 하는 기법을 시분할(Time Sharing, 시간공유) 기법이라 한다. 따라서 CPU 코어가 하나만 있어도 여러 프로그램이 동시에 실행되는 것 처럼 느낄 수 있다. 이처럼 하나의 컴퓨터 시스템이 동시에 여러 작업을 수행하는 능력을 멀티태스킹(Multitasking) 이라 한다.
스케줄링
CPU에 어떤 프로그램이 얼마만큼 실행될지 결정하는 것을 스케줄링 이라 한다. 단순 시간으로만 작업을 분할하지 않고, CPU를 최대한 활용할 수 있는 다양한 우선순위와 최적화 기법을 사용한다
멀티프로세싱
컴퓨터 시스템에서 둘 이상의 프로세서(CPU 코어)를 사용해 여러 작업을 동시에 처리하는 기술을 의미. 멀티프로세싱 시스템은 하나의 CPU 코어만을 사용하는 시스템보다 동시에 더 많은 작업을 처리할 수 있다.
멀티태스킹은 운영체제 소프트웨어의 관점이고, 멀티프로세싱은 하드웨어 장비의 관점
프로세스와 스레드
프로세스
- 프로그램은 실행 전까지는 파일에 불과
- 프로그램을 실행하면 프로세스가 만들어지고 프로그램이 실행
- 운영체제 안에서 실행중인 프로그램을 프로세스라 한다.
- 프로세스는 실행 중인 프로그램의 인스턴스
자바로 비유하면 클래스는 프로그램, 인스턴스는 프로세스
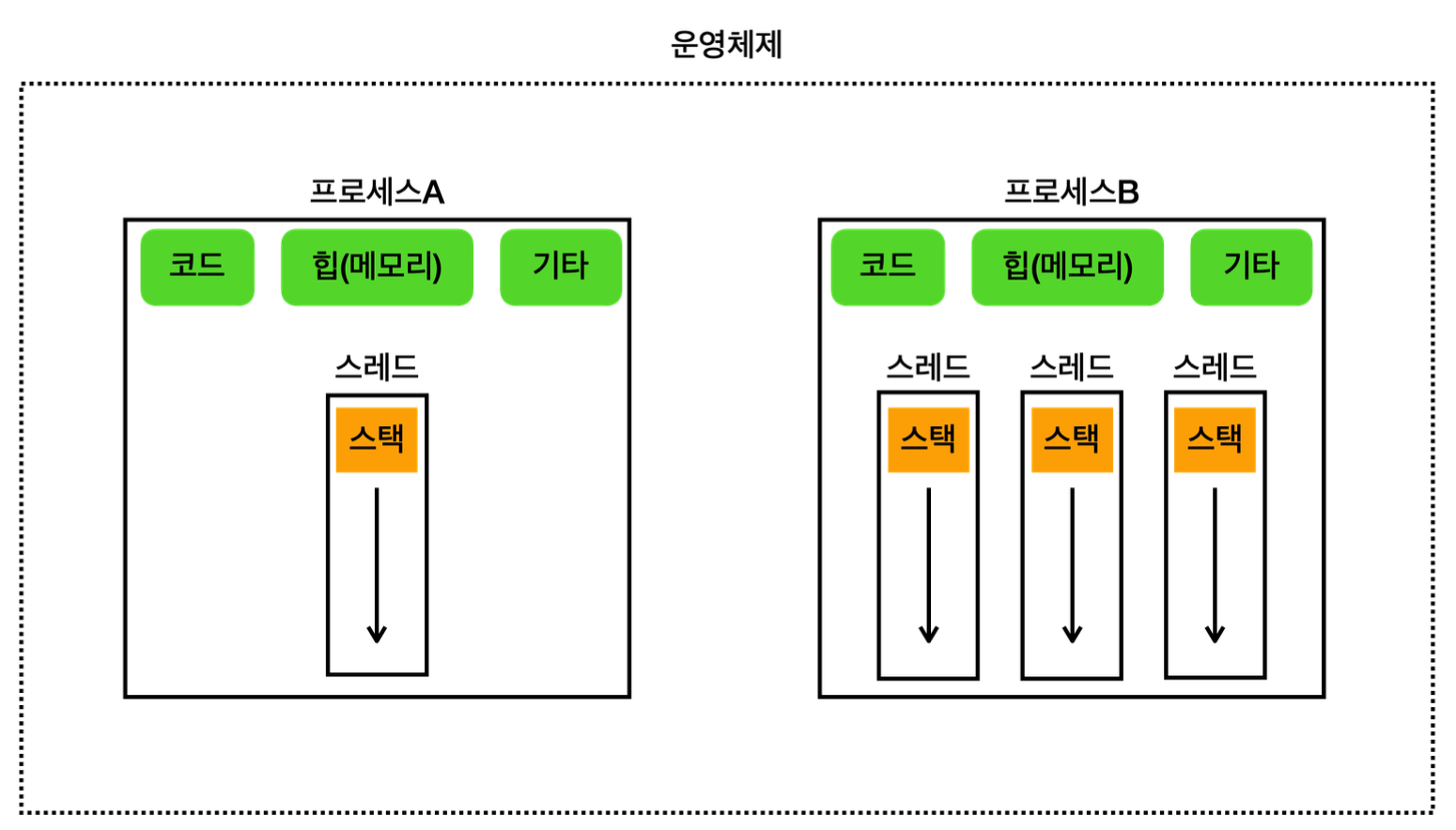
각 프로세스는 독립적인 메모리 공간을 갖고 있으며, 운영체제에서 별도의 작업 단위로 분리해서 관리된다. 각 프로세스는 별도의 메모리 공간을 갖고 있기 때문에 서로 간섭하지 않는다. 서로의 메모리에도 직접 접근할 수 없다. 즉 서로 격리되어 있기 때문에 하나의 프로세스가 충돌해도 다른 프로세스에 영향을 끼치지 않는다.
프로세스의 메모리 구성
코드 섹션: 실행할 프로그램의 코드가 저장되는 부분
데이터 섹션: 전역 변수 및 정적 변수가 저장되는 부분 (기타)
힙 (Heap): 동적으로 할당되는 메모리 영역
스택(Stack): 메서드(함수) 호출 시 생성되는 지역 변수와 반환 주소가 저장되는 영역(스레드에 포함)
스레드
- 프로세스는 하나의 스레드를 반드시 포함
- 스레드는 프로세스 내에서 실행되는 작업의 단위
- 한 프로세스 내에서 여러 스레드 존재 가능
- 이 들은 프로세스가 제공하는 동일한 메모리 공간을 공유
- 스레드는 프로세스보다 단순하므로 생성 및 관리가 가볍다
메모리 구성
- 공유 메모리: 같은 프로세스의 코드 섹션, 데이터 섹션, 힙(메모리)은 프로세스 안의 모든 스레드가 공유
- 개별 스택: 각 스레드는 자신의 스택을 갖고 있다.
프로그램을 실행하면 디스크에 있는 파일 덩어리인 프로그램을 메모리로 불러오면서 프로세스를 만들고 프로세스 안에 있는 코드가 한 줄씩 실행되는 것이다. 코드는 보통 main() 부터 시작해서 하나씩 순서대로 내려가며 실행된다.
프로세스는 실행 환경과 자원을 제공하는 컨테이너 역할을 하고, 스레드는 CPU를 사용해 코드를 하나씩 실행한다.
스레드와 스케줄링
단일코어 스케줄링
하나의 CPU에서 여러 프로세스를 번갈아 실행하는 방식.
- FCFS (First Come First Served) - 먼저 온 순서대로 처리
- SJF (Shortest Job First) - 실행 시간이 짧은 것부터 평균 대기시간 최소화하지만 기아(starvation) 문제 가능성
- Round Robin - 타임 퀀텀 단위로 돌아가며 실행. 응답시간 좋지만 컨텍스트 스위칭 오버헤드 발생
- Priority Scheduling - 우선순위 기반. Aging 기법으로 기아 문제 해결
멀티코어 스케줄링
여러 CPU 코어에 프로세스/스레드를 어떤 코어에 할당하고, 어떤 순서로 실행할지 결정하는 기법. 단일 코어는 “누구를 먼저 실행할까”만 생각하지만, 멀티코어는 “누구를 어디에 배치할까” 까지 고려
핵심 목표
처리량(Throughput) - 모든 코어를 최대한 활용해 많은 작업 처리
응답성(Latency) - Lock 대기와 Cache Miss 최소화
주요 문제와 해결책
캐시 지역성 문제(Cache Locality)
프로세스가 A코어 → B코어로 이동하면 A의 캐시 데이터를 버리고 다시 로딩해야함 (성능저하)
해결책 : CPU Affinity (친화성)
- Soft Affinity - 가능하면 같은 코어 사용 (기본동작)
- Hard Affinity - 특정 코어에만 고정
부하 불균형 (Load Imbalance)
특정 코어만 과부하, 다른 코어는 유휴 상태
해결책 : Migration
- Work Stealing : 놀고 있는 코어가 바쁜 코어의 작업을 가져옴 (Go, Java Fork/Join)
- Push Migration : 바쁜 코어의 작업을 강제로 다른 코어로 이동
동기화 오버헤드 (Synchronization)
여러 코어가 동시에 같은 데이터 접근 시 Lock 경합 발생
- 하드웨어 레벨: Cache Coherence Protocol (MESI) - CPU가 자동으로 캐시 일관성 유지
- 애플리케이션 레벨: synchronized, Lock, @Transactional 등
- 분산 시스템 레벨: Redis 분산락, DB Lock 등
해결책: Lock-Free 자료구조, CAS 사용
스케줄링 방식
| 방식 | 구조 | 장점 | 단점 |
|---|---|---|---|
| SMP | 모든 코어가 하나의 Ready Queue 공유 | 구현 단순 | Queue 접근 시 병목 |
| Per-Core Queue | 각 코어가 개별 Queue 보유 | 병목 감소 | 부하 불균형 가능 |
컨텍스트 스위칭
CPU가 실행 중인 스레드를 바꿀 때, 현재 상태를 저장하고 다음 스레드의 상태를 복원하는 과정
단일 코어에서 멀티태스킹을 하려면 스레드를 번갈아 실행해야 하는데, 나중에 다시 돌아왔을 때 어디까지 실행했는지, 어떤 값을 계산하고 있었는지 알아야 이어서 실행할 수 있음. 결과적으로 컨텍스트 스위칭 과정에는 약간의 비용이 발생한다.
멀티스레드는 대부분 효율적이지만, 컨텍스트 스위칭 과정이 필요하므로 항상 효율적인 것은 아니다.
-
백엔드 개발자가 신경 쓸 부분
상황 문제점 해결책 Redis 성능 저하 코어 이동으로 캐시 미스 taskset으로 특정 코어 고정Spring Boot Thread Pool 크기를 얼마로? 코어 수 × (1~2) 권장 DB Connection Pool 적정 크기? 코어 수 × 2 정도 시작 Docker 컨테이너 다른 컨테이너가 CPU 독점 --cpuset-cpus로 격리
출처: 김영한의 실전 자바 - 고급편